Verschiedene Text-basierte Daten per
Power Query verarbeiten
Vermutlich werden sie bei dieser Überschrift als erstes an Dateien mit der Endung *.txt denken. Diese Files sind aber nur ein Teil dessen, was aus fachlicher Sicht zu den Textdateien gehört. Es gibt (mindestens) 2 weitere Dateitypen, wovon eine weitaus öfter als die eben beschriebene Textdatei verwendet wird. Aber sehen Sie selbst …
Comma separated values
Vielleicht werden sich bei dieser Überschrift fragen, welche Dateityp hier gemeint ist. Wenn Sie jeweils das 1. Zeichen der 3 Worte nehmen, kommt dabei eine in den gewiss bekannte Datei Änderung heraus: *.csv. Es ist durchaus denkbar, dass sie jetzt innerlich „protestieren” und denken oder sagen, dass dieses doch eine Excel-Datei sei. Ganz klar und deutlich: Nein, csv ist eine reine Textdatei, die gewissen und klar definierten Regeln unterliegt. Sie können jede csv mit einem beliebigen Texteditor öffnen und sich den Inhalt betrachten. Dass sich diese Files bei einem Doppelklick darauf automatisch in Excel öffnen, das ist eine andere Baustelle. 😎
Grundsätzlich gilt, dass die verschiedenen Spalten durch einen definiertes Zeichen getrennt sind. Im US-Format ist dieses typischerweise das Komma , (daher auch die Abkürzung Csv), im deutschen Sprachbereich ist dieses meistens das Semikolon ;. Prinzipiell hängt das verwendete Default-Trennzeichen aber von den Ländereinstellungen des Betriebssystems ab. Als Besonderheit ist zu vermerken, dass Texte einer Spalte, die selbst das Trennzeichen enthalten (also beispielsweise das Komma bzw. das Semikolon) in doppelter Anführungsstriche gesetzt werden; damit wird vermieden, dass zusätzliche (und damit auch falsche) Spalten beim Import der Daten generiert werden. Reine Zahlen (ohne jegliche Zusätze einschließlich Währungsbezeichnungen) stehen ohne Gänsefüßchen in der Zeile.
Semikolon als Trennzeichen
Für die Übung laden Sie erst einmal diese gepackte zip-Datei und entpacken sie. Es wird ein eigenes Verzeichnis PQ-Import erzeugt, damit Sie einen guten Überblick behalten. Neben verschiedenen anderen Files finden Sie dort 2 prinzipiell identische csv-Dateien: Mitglieder;des;18.Dt.Bundestages.csv und Mitglieder_des_18.Dt.Bundestages.csv. Die erstgenannte Datei entspricht der deutschen Norm und die Spalten sind mit einem Semikolon getrennt; die zweitgenannte enthält das Komma als Trennzeichen für die einzelnen Spalten. Eine weitere Besonderheit der zweiten Datei werden Sie später noch kennenlernen. Sie werden anschließend beide Files per Power Query einlesen und in einer Tabelle speichern. Legen sie nun eine neue, leere Arbeitsmappe an. – Das Vorgehen ist dann für beide Dateien grundsätzlich sehr ähnlich. Und bedenken Sie, dass Sie die Files nicht per Doppelklick sondern mithilfe des Power Query öffnen!
- Aktivieren Sie die Power Query Funktionalität entweder über das Menü gleichen Namens (Excel 2010⁄2013) bzw. Daten.
- Neue Abfrage | Aus Datei | Aus csv
- Im Datei-Dialog wählen Sie zu Beginn die Datei Mitglieder;des;18.Dt.Bundestages.csv. Importieren
- Es zeigt sich die Vorschau der zu importieren den Daten in einem Dialog:
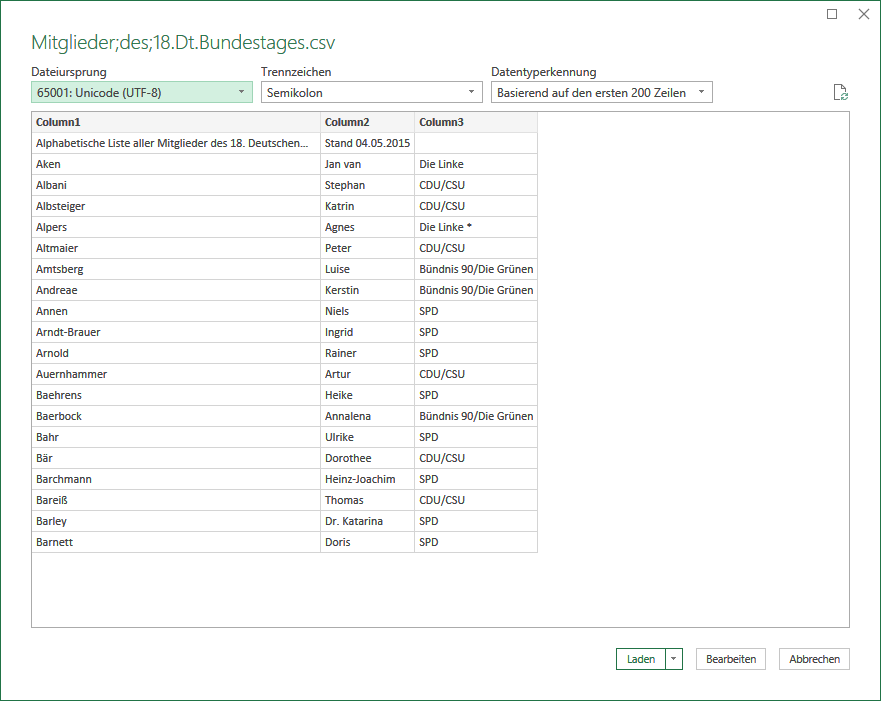
Preview der Semikolon-getrennten csv-Datei
Das sieht ja schon erst einmal ganz gut aus. Das Kombinationsfeld Dateiursprung ist für Sie immer dann von Bedeutung, wenn Sonderzeichen wie beispielsweise die deutschen Umlaute oder das ß nicht korrekt dargestellt werden. In den meisten Fällen wird aufgrund der Daten die richtige Codierung erkannt, in Einzelfällen ist hier eine Änderung an dieser Stelle erfolgversprechend. – Als Trennzeichen wurde das Semikolon hier korrekt erkannt. Hier haben sie aber auch die Möglichkeit, „exotische” Trennzeichen wie beispielsweise das Pipe-Symbol (|) einzugeben. So weit, so gut. Aber beim genauen hinsehen werden Sie vielleicht erkennen, dass dort ein Punkt nicht so ist wie erwartet: Die 1. Zeile der csv-Daten wurde nicht als Überschrift verwendet. Und Sie hatten auch keine Möglichkeit, das im Vorwege auszuwählen. Aber gut, ein Klick auf die Schaltfläche Bearbeiten und die Daten werden in den Power Query Editor geladen. Hier stellt sich das ganze nun so dar:
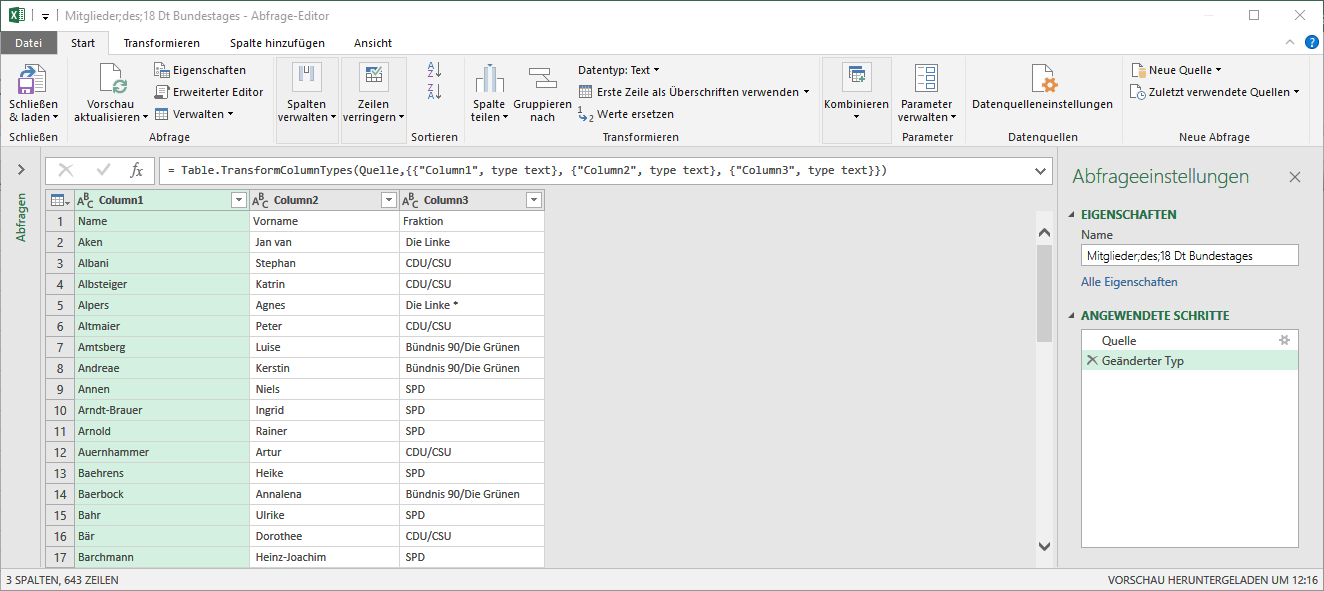
Ansicht direkt nach dem Import der Daten
Wie bereits in der Vorschau zu sehen war, sind die einzelnen Spalten korrekt getrennt; die Umlaute werden auch richtig dargestellt; und die Überschriften der einzelnen Spalten wurden eigenmächtig durch Power Query erstellt. Auf den ersten Blick bietet sich diese Möglichkeit an, das zu korrigieren: Die Überschriften von Hand ändern und dann die 1. Datenzeile löschen. – Power Query bietet Ihnen aber eine weitaus elegantere Möglichkeit: Im Register Start, Gruppe Transformieren einfach ein Klick auf den Menüpunkt Erste Zeile als Überschriften verwenden und die Liste ist perfekt.
Jetzt bleibt nur noch ein Klick auf Schließen & laden, um die Daten in ein neues Arbeitsblatt zu speichern. Wollen Sie die Abfrage in das leere Blatt Tabelle1 schreiben, dann Klicken Sie im Menü Start in der Gruppe Schließen nicht auf das Symbol (Icon) sondern auf den Text darunter und wählen dort im Untermenü bewusst den Punkt Schließen und laden in… und dort dann natürlich Bestehendes Arbeitsblatt. Dann kontrollieren Sie den Ziel-Ort, Laden und die Daten der Abfrage werden am gewünschten Ort abgelegt.
Hinweis: Sehen Sie sich einmal mit einem Editor (Notepad, Notepad++, …) die csv-Datei an und achten Sie auf die Leerzeichen nach den Semikola. – Betrachten Sie sich das Endergebnis in der durch PQ erstellten Tabelle. Laden Sie nun noch einmal das gleiche File auf bekanntem Wege (beispielsweise per Doppelklick) in Excel. Fällt Ihnen etwas auf? Notfalls wird Ihnen die Funktion LÄNGE() ein Licht aufgehen lassen … 😛
Komma – getrennt
Bei den ersten Schritten ist das Vorgehen absolut identisch wie bei der mit Semikola getrennten csv-Datei. Nur dass sie hier die Datei Mitglieder_des_18.Dt.Bundestages.csv aus dem entpackten Ordner wählen. Sie können für diese Übung entweder ein neues Workbook anlegen oder aber (sinnvollerweise) in der aktuellen Arbeitsmappe bleiben. Wie bereits zuvor angedeutet, gibt es hier einen weiteren aber entscheidenden Unterschied: Die 1. Zeile der csv-Daten enthält nicht die Spaltenüberschriften sondern einen erklärenden Text, der nicht zum Datenbestand gehört.
Verschiedene Warenwirtschaftssysteme erzeugen beim Export als sogenannte Excel Datei eine *.csv mit einer oder mehreren Zeilen eines Kopfbereichs, der mit den zu verarbeiteten Daten relativ wenig zu tun hat und in keinem Fall in die auszuwertenden Daten mit übernommen werden soll. Hier stellt sich das nun so dar:
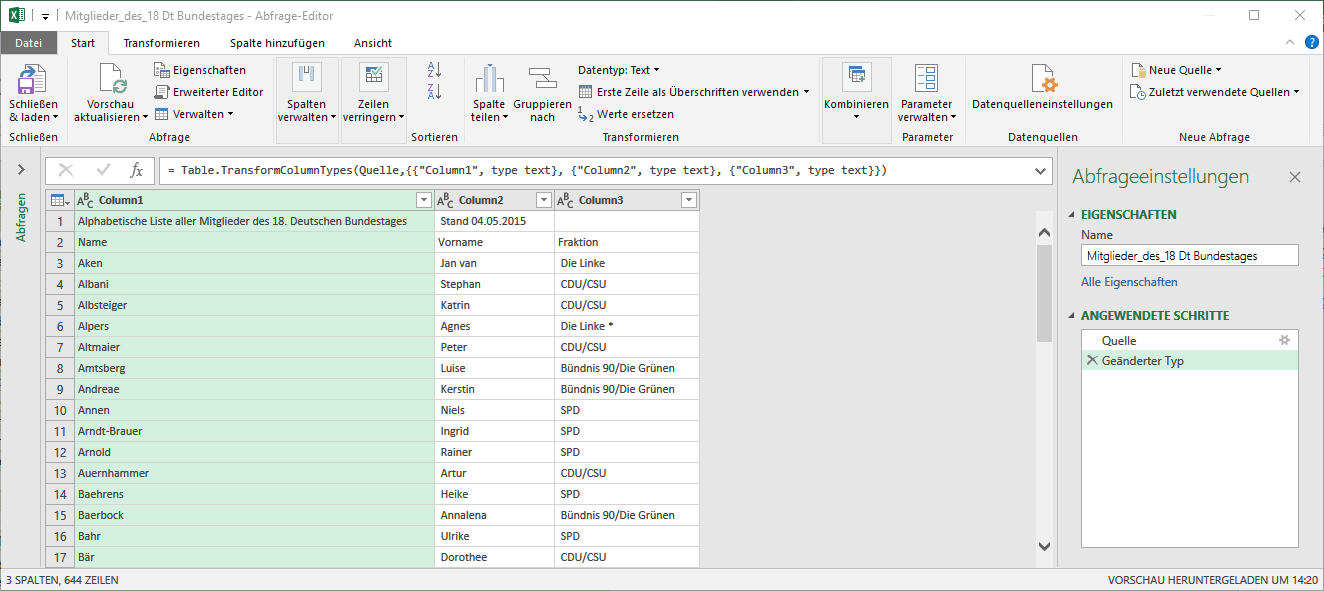
Die 1. Zeile enthält eine Kopfzeile, aber nicht die Überschrift
Klicken Sie hier auf das Symbol Zeilen verringern | Zeilen entfernen | Erste Zeilen entfernen und tragen Sie dann bei Anzahl von Zeilen eine 1 ein, denn es soll ja nur (beginnend mit der 1. Zeile) 1 Zeile entfernt werden. – Anschließend werden sie wieder den Menüpunkt Erste Zeile als Überschriften verwenden auswählen. Danach reicht ein Klick auf das Symbol Schließen & laden, denn die Abfrage soll ja in einem neuen Arbeitsblatt gespeichert werden.
Nicht-Standard Trenner und Anführungsstriche
Den Programmierern von einschlägigen Warenwirtschaftssystemen, etc. ist zwischenzeitlich durchaus bewusst, dass die Werte der Spalten in Gänsefüßchen eingefasst werden müssen, wenn diese in irgendeiner Form das Trennzeichen enthalten. Und darum spielt dieses Format auch mitunter (eigentlich: inzwischen wieder) eine Rolle. Ein klassisches Beispiel wäre, dass US-Daten numerische Werte mit Tausendertrennern enthalten und diese ‑aus welchen Gründen auch immer- als Text in der csv stehen. Vielfach ist es das Währungs-Symbol wie beispielsweise das $-Zeichen. Und da dieses ja keine Zahlen sondern Text sind, wird der jeweilige Wert in Anführungszeichen eingefasst. Das bedeutet: Der Spaltentrenner ist wegen der US-Daten ein Komma, genauso wie der Tausendertrenner in den als Text gespeicherten Zahlen. 💡 – Um sie nicht allzu sehr zu verwirren, habe ich die nun schon mehrfach genutzten Daten der Abgeordneten etwas abgeändert: Statt des Semikolons oder eines Kommas als Spaltentrenner habe ich den Bindestrich verwendet, und da dieses Zeichen auch Bestandteil unterschiedlicher Daten ist (z.B. Zeile 21) sind die Inhalte jeder Spalte (natürlich) in Anführungszeichen eingefasst:
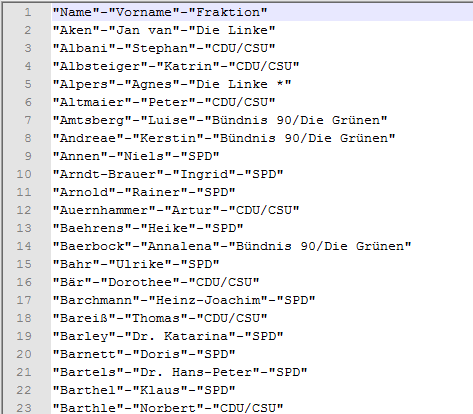
Die Original-csv-Daten im Editor
Es ist durchaus denkbar, dass sie Dateien in einem solchen Format bekommen und in Power Query aufbereiten sollen. Es muss nicht der Bindestrich sein, meistens ist das (wie schon erwähnt) ein Komma oder das Semikolon, welches für die Verwendung der Anführungszeichen verantwortlich zeichnet. Aber hier zählt das Prinzip und Sie erkennen auch gleich, wie Sie mit ungewohnten Trennzeichen umgehen können. Der Ablauf eines solchen Imports ist aber an entscheidenden Stellen um einiges anders, als wie sie es bis hierher kennengelernt haben…
Beginnen Sie wie bisher mit dem Import der csv-Datei. Für diese Übung verwenden Sie dieses File: Mitglieder-des-18.Dt.Bundestages-’-’.csv als Objekt der Bearbeitung. Bereits das erste Dialogfenster sieht ganz anders aus als gewohnt; nur eine Spalte und offensichtlich keine Möglichkeit, in Sachen Trennzeichen irgend eine Änderung vorzunehmen:
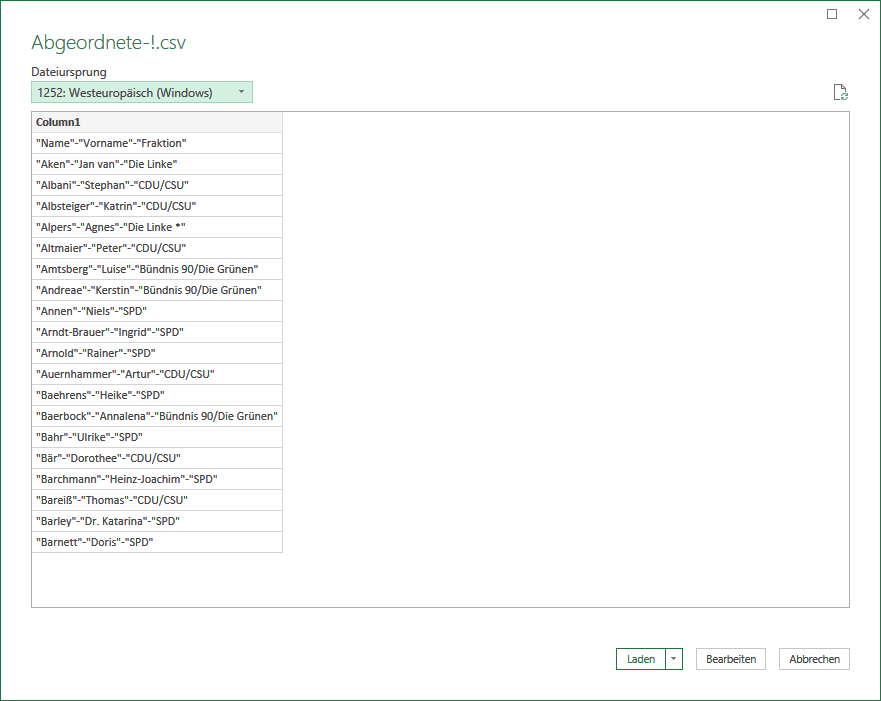
Die Vorschau ist etwas gewöhnungsbedürftig
- Folglich bleibt nur die Möglichkeit, Bearbeiten anzuklicken.
- Es ist nicht wirklich überraschend, dass sich nach dem Import in den Editor praktisch nichts gegenüber dem Preview geändert hat:
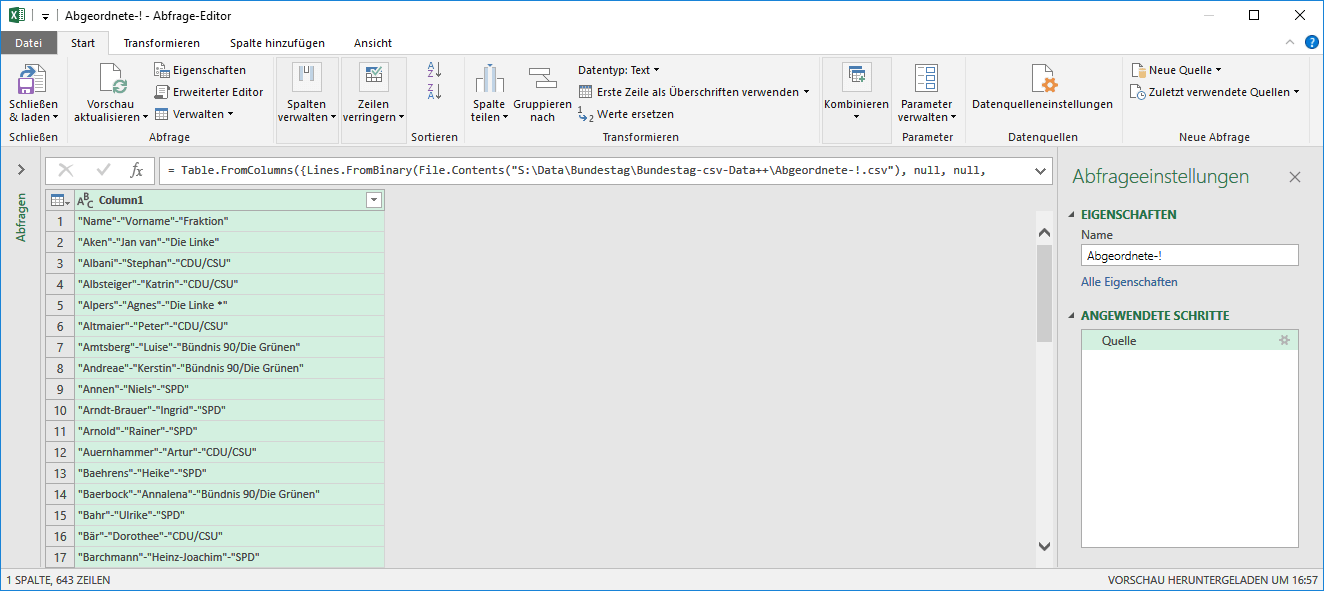
Eine einzige Spalte ohne direktes Angebot zum splitten …
- Auch wenn es „in den Fingern juckt“, die Überschrift Column1 bleibt erst einmal bestehen.
- Im Register Start Gruppe Transformieren Klicken Sie auf das Symbol Spalte teilen.
- Selbstverständlich werden Sie Nach Trennzeichen teilen.
- Da der Bindestrich nicht als Trennzeichen angeboten wird, wählen Sie im Menüband den Punkt –Benutzerdefiniert– aus.
- Tragen Sie in das gerade eingeblendete leere Textfeld den Bindestrich - ein.
- Alle weiteren Einstellungen belassen Sie so, wie sie sind; OK.
Die Spalten sind ja offensichtlich korrekt getrennt worden. Was allerdings etwas irritieren kann: Statt 3 sind es 5 Spalten. Ursachenforschung ist hier (ausnahmsweise) einmal nicht wichtig, aber sie sollten in jedem Fall kontrollieren, ob dort nicht doch irgendetwas sinnvolles dort drinnen steht. Dazu Klicken Sie einfach auf den Dropdown-Pfeil der Spalten Column1.4 und Column1.5 und sie werden erkennen, dass dort ausschließlich die Werte (NULL) und (LEER) enthalten sind. Als Folgerung können Sie diese beiden Spalten einzeln nacheinander oder gemeinsam löschen.
Bleibt noch als letzter Schritt, die Überschriften durch den Inhalt der 1. Zeile zu ersetzen. Das Vorgehen kennen Sie ja bereits: In der Gruppe Transformieren auf Erste Zeile als Überschrift verwenden Klicken und der Import der csv ist komplett. Was noch bleibt: Schließen & laden.
Text-Dateien (*.txt)
Die Definition einer Datei mit der Endung *.txt ist in Bezug auf Tabellen und Tabellenkalkulation durchgängig so, dass ein Tabulator-Zeichen Tab die Spalten voneinander separiert. Man spricht allgemein von Tab-getrennten Daten. Und das unterscheidet nun solch ein File (Mitglieder_des_18.Dt.Bundestages_Tab.txt) von einer „ganz normalen” csv-Datei? Nun ja, wenn sie die Dateiendung und das Trennzeichen außer acht lassen: nichts. Das Vorgehen ist absolut identisch mit dem bei einer Standard-csv Datei. Und Power Query erkennt natürlich auch das Trennzeichen von alleine. Mehr gibt es dazu nicht auszuführen.
Text-Dateien (*.prn)
Fast schon antiquarisch mutet diese Form der Textdateien an. Aber es gibt verschiedene Systeme, welche diese Systematik noch anwenden. Sehen Sie sich ein Beispiel in der Datei Mitglieder des 18.Dt.Bundestages Text.prn an:

Diese Text-Dateien haben immer eine feste Breite je Spalte
Der Screenshot hierüber wurde von einem Text-Editor erstellt. Sie erkennen, dass jede Spalte die gleiche Breite hat und der Eintrag erforderlichenfalls mit Leerzeichen aufgefüllt wurde. Für sie bedeutet das, dass sie auf jeden Fall die Definition, die Struktur, die Länge der einzelnen Spalten kennen müssen.
Wenn Sie diese Zahlen haben, brauchen Sie sich um nichts weiteres zu kümmern. Wenn das nicht der Fall ist, dann gibt es verschiedene Wege, um die Breite der einzelnen Spalten festzustellen. – Wenn sie solch eine Datei nur einmalig in Power Query importieren wollen, dann fragen Sie sich, ob es den Aufwand wert ist. Ob nun ein- oder mehrmalig, ich schlage ihnen folgende Vorgehensweise vor:
- Laden Sie die *.prn in ein leeres Arbeitsblatt des Excel (über Datei öffnen, Typ: Textdateien)
- Es öffnet sich der Textkonvertierungs-Assistent und der stellt automatisch fest, dass die Spalten eine Feste Breite haben
- Markieren Sie das Kästchen Die Daten haben Überschriften, Weiter >
- Die Spaltenbreiten werden fast korrekt vorgegeben. Nur auf Position 84 sollten Sie den Spaltenteiler beispielsweise per Doppelklick darauf entfernen. Sie können sich jetzt die jeweiligen Positionen (42 und 75) notieren.
- Da alle Spalten dem Datenformat Standard entsprechen, können Sie jetzt schon auf Fertig stellen Klicken.
Für eine einmalige Aktion können Sie die nun erstellte Liste einfach über Aus Tabelle in Power Query einlesen. Wenn beispielsweise ihr Warenwirtschaftssystem diese Form der tabellarischen Text-Ausgabe stets verwendet und nicht die erforderlichen Spaltenbreiten mit angibt, können Sie diese (einmalig) beispielsweise so ermitteln:
- Schreiben Sie in (beispielsweise) Zelle F1 diese Formel:
=MAX(LÄNGE(A:A))und schließen Sie diese Formel mit StrgShiftEingabe ab.
In der Editierzeile wird die Formel nun mit geschweiften Klammern { … } dargestellt, welche sie nicht mit eingeben dürfen. Sie sind ein Zeichen dafür, dass es sich um eine sogenannte Array- Formel handelt. – Ziehen Sie nun per Ausfüllkästchen diese Formel noch 2 Spalten nach rechts und sie erhalten das Ergebnis der jeweiligen Spaltenbreite. In diesem Fall sind das 42, 23 und noch einmal 23 Zeichen.
Jetzt, wo sie nun die erforderlichen Werte haben, können Sie mit dem Power Query-Import beginnen. Wie üblich gehen Sie in Excel über das Register Daten | Neue Abfrage | Aus Datei | Aus Text. Wechseln Sie erforderlichenfalls zu dem Ordner, wo die prn-Datei gespeichert ist, markieren Sie das File und Importieren.Das darauffolgende Preview finde ich immer wieder faszinierend:
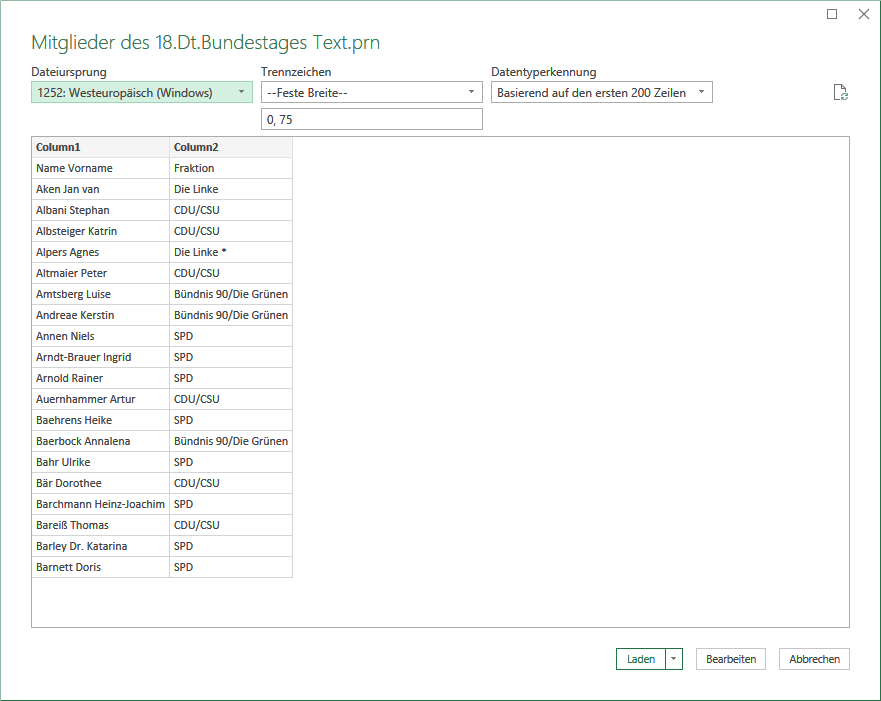
Zumindest die feste Spaltenbreite stimmt …
Gemäß dem uralten Satz „Augen zu und durch” einfach nur auf Bearbeiten Klicken. Und vom Grundprinzip her scheint da ja zu mindestens einiges richtig zu sein. Wahrscheinlich sieht es bei Ihnen nun sehr ähnlich aus wie bei mir:
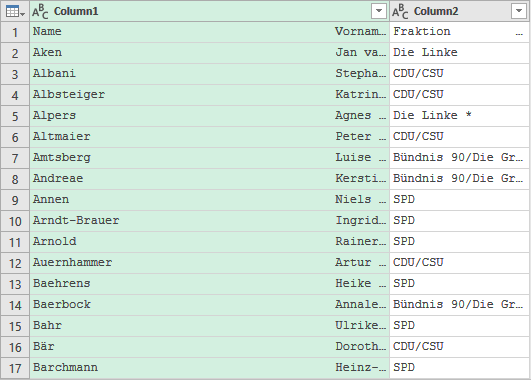
Direkt nach dem Importieren sind es nur 2 Spalten …
Alle Vornamen haben am Ende das Auslassungszeichen …, bei der Fraktion ist das immer bei Bündnis 90/Die Grünen der Fall. – Klar ist, dass in Column 1 2 Spalten zusammengefasst sind und diese getrennt werden müssen.
Erforderlichenfalls markieren Sie diese Spalte und dann Spalte teilen. Hier wählen Sie dann Nach Anzahl von Zeichen und geben im Dialogfenster die Länge der 1. Spalte als Zahl ein: 42. Da die (künftige) Spalte mit den Vornamen nicht auch so breit werden soll, markieren Sie bei Teilen den Options-Button Einmal, so weit links wie möglich. Nach einem OK stimmen zumindestens die Spalten an sich. Jetzt steht in der 1. Zeile jeder Spalte die korrekten Überschrift. Darum ein Klick auf Erste Zeile als Überschriften verwenden und das ganze hat schon richtig Stil. Ich ermuntere Sie, trotz der angezeigten Auslassungszeichen einfach auf Schließen & laden zu Klicken. Und Voila, das Ergebnis überzeugt.
Damit sind jetzt die wichtigen Importmöglichkeiten von textbasierten Dateien besprochen. Auch wenn streng genommen Importe aus dem Web auch dazugehören würden, weil hier auch nur Text übertragen werden, sind diese an anderen Stellen hier im Blog beschrieben worden.
| Übersicht der Beiträge Power Query Einstieg | |
| Lerneinheit 1 (1) | Web-Abfragen mit Power Query – Teil 1 |
| Lerneinheit 1 (2) | Web-Abfragen mit Power Query – Teil 2 |
| Lerneinheit 2 | Grundlegende Menü-Elemente Kurzreferenz |
| Lerneinheit 3 | Filtern und teilen |
| Lerneinheit 4 | Text-basierte Files importieren |
Bundesweite ✉ Schulungen ✉ durch unseren Sponsor GMG Computer-Consulting
Hat Ihnen der Beitrag gefallen?
Erleichtert dieser Beitrag Ihre Arbeit?
Dann würde ich mich über einen Beitrag Ihrerseits z.B. 2,50 € freuen …