Xtract: Sonderzeichen außerhalb des lateinischen, deutschen Alphabets erkennen und für spätere Verwendung separieren. Teil 1: vollkommen funktionierende Basics, „saubere” Datenbasis.
Wissensstand: Level 3 ⇒ Excel GUT!, mindestens Basis-Kenntnisse in Power Query
In einem Excel-Forum hat ein Fragesteller um die Lösung nachgefragt, wie er spezielle Duplikate erkennen und entfernen kann. Das „spezielle” bezog sich darauf, dass bei Namen für die gleiche Person mitunter verschiedene Schreibweisen verwendet worden sind; das können beispielsweise Umlaute sein, die teilweise (korrekt) als Umlaut (zum Beispiel Ü) geschrieben werden, mitunter aber auch der Internationalität wegen als Ue. Oder aber der Vorname René auch einmal in eingedeutscht Schreibweise als Rene.
Der Fragesteller wollte nun insbesondere die zweitgenannten Sonderzeichen erkennen und als Liste darstellen, um die entsprechenden Datensätze zu korrigieren und anschließend eventuelle durch die Korrektur entstandenen Duplikate zu entfernen. Der Hilfe suchende hat (natürlich) keine Muster-Datei beigefügt was mich dazu veranlasst hat, eine eigene Namens-Aufstellung zu erstellen und dann zu nutzen.
Da im 20. Deutschen Bundestag verschiedene Abgeordnete vertreten sind deren Namen Zeichen enthält, die außerhalb des Bereichs des deutschen, 26 Zeichen umfassenden Alphabets als auch der Umlaute bzw. des ß liegen, habe ich mir solch eine Liste aus dem Internet gezogen. Die Bundestagsverwaltung selbst bietet mir derzeit (dem Anschein nach) keine entsprechende direkt herunterladbare Datei an, darum habe ich erst einmal per copy/paste den relevanten Inhalt der entsprechenden Seite in ein Excel-Arbeitsblatt eingefügt.
Ich empfinde das Ergebnis als absolut benutzerunfreundlich. Aber immerhin ist das eine gute Vorlage für das Thema „Aufarbeiten von schlecht strukturierten Daten”. 😉 Hier können Sie die von mir erstellte Rohversion der *.xlsx herunterladen. Hinweis: In diesem Beitrag werden Sie die Daten (die Datei) nicht brauchen, sehr wohl aber in einem weiteren Beitrag zu diesem Thema.
Eine im Endeffekt wesentlich leichtere Möglichkeit und auch noch ein besseres, weil datenseitig umfangreicheres Ergebnis bietet hier Wikipedia mit einer sehr ausführlichen Aufstellung. Dort ist ein direkter Import in Power Query über Daten | Aus dem Web möglich. 🙂 Ein Tipp: Es gibt eigentlich nur 1 Tabelle (Table), welche (neben anderen Spalten) Name und Fraktion bzw. Partei darstellt.
Da sich diese Übersicht (von Wikipedia) hervorragend für Übungen aller Art eignet, würde ich die Abfrage per Schließen & laden in… sichern, in das leere Arbeitsblatt Tabelle1 positionieren, diese Datei sofort ohne Änderungen abspeichern und anschließend für diese zuerst anstehende Übung in Sachen Sonderzeichen noch einmal öffnen. Mein Vorschlag: Sofort nach dem Öffnen unter einem anderen Namen (beispielsweise Sonderzeichen finden) abspeichern, damit das unveränderte Original erhalten bleibt. Diese Vorgehensweise hat sich in meinem Excel-Leben weit mehr als ein Mal bewährt!
Im ersten Schritt dieser Übung / Lösung geht es um die erste Zeile der Abfrage, welche ja nur eine Wiederholung der Überschrift ist. Also werden Sie diese Zeile löschen. Und da es bei der gegebenen Aufgabe ja nur um die besonderen Zeichen in den Namen geht, lösche ich alle Spalten außer Name und belasse vielleicht auch Fraktion (Partei). Und um die Spalte Name für Vergleichszwecke unverändert zu lassen, erstelle ich hiervon eine Kopie, wo ich später bei Bedarf Änderungen nach Lust und Laune vornehmen kann. PQ stört sich nicht an dem Duplikat, denn die Spaltenüberschrift unterscheidet sich ja automatisch; und ich bin auf dem sicheren und übersichtlicheren Weg.
Hinweis: Ich werde Sie in mehreren Schritten zum Ziel führen, denn auch ich mache bei mir selber immer wieder die Erfahrung, dass ich nicht immer alles konsequent bis zum Ende durchdenke und beachte. Noch einmal zur Erinnerung bzw. zur Klarstellung: Es soll eine Liste erzeugt werden, wo alle nicht ursprünglich zur deutschen Sprache gehörenden Zeichen in den Namen (der Abgeordneten) aufgeführt sind. Da diese Aufstellung der Namen nur im deutschen Sprachgebrauch genutzt werden soll, können Umlaute bestehen bleiben und brauchen nicht geändert, nicht in der Liste aufgeführt werden. Zugegeben, im ersten beschriebenen Schritt werden auch die Umlaute als Sonderzeichen ausgegeben, aber das wird dann auch rasch geändert.
Gehen Sie über Spalte hinzufügen | Benutzerdefinierte Spalte und tragen Sie im Dialog bei Neuer Spaltenname beispielsweise Sonderzeichen ein. Als Benutzerdefinierte Spaltenformel schreiben Sie diesen Text (diese Formel):
Text.Remove([Name],{"A".."Z","a".."z"})
Beachten Sie bitte die exakte Groß- Kleinschreibung und dass in der Formel nach dem Komma und nach dem letzten " eine geschwungene und keine runde Klammer steht. – Sie erkennen, dass in dieser Spalte die meisten Zeilen leer sind aber auch alle Umlaute und sonstige nicht zum typischen Alphabet gehörende Zeichen aufgelistet sind. Unter dem Aspekt, dass die Umlaute und das ß nicht als Sonderzeichen ausgewiesen werden sollen, ergänzen oder ändern Sie die obige Formel so:
Text.Remove([Name],{"A".."Z","a".."z","Ä","ä","Ö","ö","Ü","ü","ß"})
Sie sehen, dass nun deutlich weniger Zeilen mit einem sichtbaren Eintrag erhalten geblieben sind. Und vielleicht haben Sie auch bemerkt, dass es keine einzige Zeile mit dem Wert null gibt? Aber auch dazu später mehr.
Für einen schnellen Überblick können Sie die Spalte Sonderzeichen natürlich dahingehend filtern, dass alle „leeren” Zeilen nicht angezeigt werden. Und gewiss fällt Ihnen bei diesem Filtervorgang auf, dass die ersten drei Einträge der (automatisch sortierten) Liste sich scheinbar gar nicht unterscheiden. Dieses Phänomen sollten Sie noch etwas näher erkunden … 🙂 Erforderlichenfalls löschen Sie wieder einen gesetzten Filter.
Wie schon angemerkt: Keine einzige Zelle der Spalte Name ist wirklich leer, denn dann würde bei Sonderzeichen im Filter-Dialog der ungefilterten Abfrage (NULL) oder (leer) aufgelistet sein. Der vielleicht sicherste Weg zur „Erleuchtung” ist, eine neue Spalte mit folgender Formel anzulegen:
=Text.Length([Sonderzeichen])
und benennen Sie die Spalte beispielsweise Textlänge (Sonderzeichen). Sie können es aber auch bei dem angegebenen Defaultwert „Benutzerdefiniert” belassen, denn Sie werden diese Spalte nur kurz nutzen.
Sie werden erkennen, dass in den Zeilen mit diesen „inhaltslosen” Zellen die Werte 1 bis 3 ausgegeben werden. Mein Tipp: Ich filtere vorübergehend die Spalte Sonderzeichen dergestalt, dass nur die ersten 3 leer erscheinenden Zellen erhalten bleiben. Nach einer Kontroll-Auswertung und Analyse entferne ich natürlich wieder den Filter-Vorgang im rechten Seitenfenster.
Und das zwischenzeitliche Ergebnis lässt Sie gewiss rasch zur Erkenntnis kommen, dass es sich dabei um Leerzeichen handelt. Ein kurzer Blick in das jeweilige Feld Name wird Ihnen auch bestätigen, dass der Name in irgendeiner Form bzw. an irgendeiner Stelle Leerzeichen enthält. Und klar, die sollen natürlich auch nicht als Sonderzeichen sondern als „ganz normale Zeichen” gewertet werden. Also ergänzen Sie die Benutzerdefinierte Formel auch noch um das Argument , " " :
Text.Remove([Name], {"A".."Z", "a".."z", "Ä", "ä", "Ö", "ö", "Ü", "ü", "ß", " "})
Hinweis: In der durch Sie importierten Datei sind weder führende noch angehängte Leerzeichen enthalten, denken Sie aber bei Importen eigener Daten auch an die Möglichkeit und bereinigen Sie bei Bedarf die Datenquelle in Excel oder Power Query entsprechend.
Wie auch immer, Textlänge (Sonderzeichen) wird nun (nach dieser Änderung) für alle leer erscheinenden Felder der Spalte Sonderzeichen die Zahl 0 anzeigen, alternativ die 1 oder 2. Idealerweise filtern Sie Textlänge (Sonderzeichen) dergestalt, dass nur Zellen mit dem Wert >0 erhalten bleiben.
Nun ist das Ganze durch die wesentlich geringere Zahl der Datensätze deutlich übersichtlicher. Aber 67 Zeilen bzw Namen mit Sonderzeichen sind immer noch deutlich zu viel. Und klar, das Zeichen - (Bindestrich, Minus) ist bei den Doppelnamen vertreten. Sie ahnen es, die benutzerdefinierte Funktion/Formel muss noch einmal um dieses Zeichen ergänzt werden; das können Sie aber nun auch ohne meine Hilfe. 😎
Oh ja, in der gefilterten Query sind nur noch 13 Zeilen, das scheint zu passen. Scheint aber nur der Fall zu sein, denn bei verschiedenen Abgeordneten ist der zweite Vorname nach dem ersten Zeichen mit einem Punkt nach dem ersten Zeichen abgekürzt. Ich denke, dass auch dieses keines der aufzulistenden (und später anzupassenen) Sonderzeichen ist. Darum gehört auch der Punkt in die Text.Remove()-Formel.
Bingo, nun sind in den 11 Zeilen nur noch „echte” Sonderzeichen aufgeführt. Und das war das erwünschte Ziel, oder?… Nicht ganz, denn es sind ja noch Duplikate wie beispielsweise das é enthalten. Sonderzeichen markieren und über Transformieren | In Liste konvertieren erzeugen Sie eine Liste der gefilterten Sonderzeichen. Duplikate entfernen und gerade noch 5 verbleibende (unterschiedliche) Sonderzeichen liegen als PQ-Liste vor. Vermutlich werden Sie nun diese Liste wieder zu einer Tabelle/Abfrage konvertieren, um damit später in gewohnter Weise zu arbeiten. Naturgemäß bietet es sich an, die Liste oder Abfrage zu Sonderzeichen-Unikate umzubenennen.
Na ja, jetzt haben Sie zwar die eigentlich angestrebte Liste aber alle anderen Spalten sind nicht mehr existent. Und Sie fragen sich gewiss zu Recht, warum denn die Spalte Name – Kopie erstellt worden ist… 😕 Ich sehe hier zwei pragmatische Möglichkeiten, den „Gordischen Knoten” zu entflechten:
1) Falls Ihre Excel-Version einigermaßn aktuell ist, können Sie so vorgehen: Markieren Sie im rechten Seitenfenster bei Angewendete Schritte jene Zeile, wo Sie Sonderzeichen in eine Liste konvertiert haben; das ist hier die Zeile Sonderzeichen. Rechtsklick und wählen Sie die Option Vorherige extrahieren :
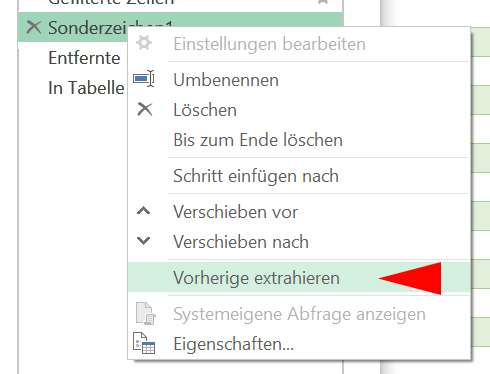
Recht unbekannt aber wirkungsvoll!
Es folgt ein Dialog, wo Sie der neu zu erstellenden Abfrage einen Namen geben werden, hier beispielsweise Namen-Liste :
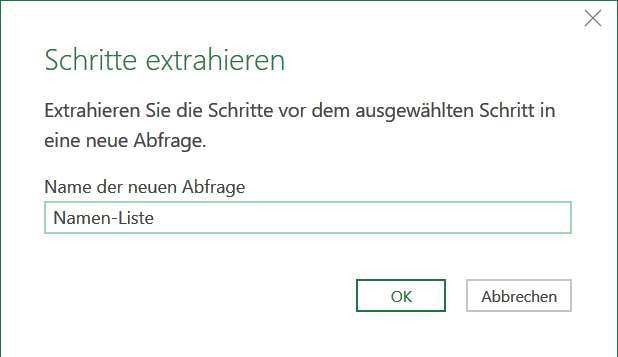
Der Name der neuen Abfrage
Anschließend sind 2 Abfragen existent, die eben erstellte und jene, wo nur die Sonderzeichen-Unikate enthalten sind. Dieser letztgenannten Query werden Sie eventuell einen anderen Namen geben.
2) Sie löschen alle Schritte ab dem Punkt, wo Sie aus der Spalte Sonderzeichen eine Liste erzeugt hatten. Dann Sonderzeichen markieren und per Rechtsklick Als neue Abfrage hinzufügen. Dann haben Sie auch die entsprechende Liste und Sie können die Duplikate entfernen und anschließend eine Abfrage daraus erstellen.
Der Hilfe suchende Fragesteller (oder auch Sie) könnte(n) nun die ursprüngliche Abfrage als Nur Verbindung speichern und anschließend die vermutlich auch als Nur Verbindung gespeicherte Tabelle in ein neues Arbeitsblatt oder eine definierte Position eines beliebigen Arbeitsblatts speichern (siehe auch hier). Natürlich sind bei diesen wenigen Zeichen einfach Ersetzen-Vorgänge ein denkbarer Weg, ansonsten kann Power Query auch mit größeren zu ersetzenden Datenmengen umgehen und Ihnen die Arbeit erleichtern.
Im allerersten Teil dieses Beitrages habe ich Ihnn aufgezeigt, dass es seitens der Bundestagsverwaltung (derzeit) keine Möglichkeit gibt, die Namen und Fraktionen der Abgeordneten direkt herunterzuladen; und ich hatte Ihnen auch einen Link angeboten, wo ich bereits per copy/paste eine Excel-Mappe erstellt habe. Die anfängliche Aufbereitung der Daten ist komplett anders als in der Datei aus dem Wikipedia-Import. Zwei Möglichkeiten mit einer anderen Möglichkeit des Extrakts der Sonderzeichen finden Sie im Beitrag Sonderzeichen erkennen und definieren (2) und ohne Bestimmung der Sonderzeichen aber einer weiteren Möglichkeit der Aufbereitung der „gewöhnungsbedürftigen” (kopierten) Daten in Sonderzeichen erkennen und definieren (3).
Rückmeldungen / Feedback gerne per Mail an mich (G.Mumme@Excel-ist-sexy.de)
Hat Ihnen der Beitrag gefallen?
Erleichtert dieser Beitrag Ihre Arbeit?
Dann würde ich mich über einen Beitrag Ihrerseits z.B. 2,50 € freuen … (← Klick mich!)