Xtract: Import von Daten einer externen Datei im Text-Format (*.csv, *.txt, *.prn, …) mittels Power Query. Dieser Beitrag ist für absolute Einsteiger ohne Vorwissen geeignet. Teil 2 (hier finden Sie Teil 1, „echte” *.csv, keine Besonderheiten)
Wissensstand: Level 1 ⇒ Power Query für Einsteiger – Keine Vorkenntnisse in PQ
Sonderfälle
Komma-Separator, CodePage, Leerzeichen
Hinweis: Sie können alle hier benötigten Dateien in 1 zip-Datei herunterladen!
Laden Sie erst einmal diese Datei (Mitglieder_des_18.Dt.Bundestages.csv) herunter. Es sind auch die Abgeordneten des 18. Deutschen Bundestages, dieses Mal aber alphabetisch geordnet. Das ist beileibe nicht die eigentliche bzw. einzige Besonderheit. Wenn Sie das File nach dem Download an Ihrer Wunschposition gespeichert haben, dann „öffnen” Sie bitte die Datei. Nein, nicht mit Excel, denn die *.csv-Dateien haben bekanntlich per Default zwar ein Excel-ähnliches Symbol sind aber reine Textdateien. Also ein Rechtsklick auf den Filenamen und Öffnen mit auswählen. Hier bietet sich der Windows-eigene Editor Notepad an; ich verwende übrigens den frei verfügbaren und kostenlosen „großen Bruder” Notepad++. – Ihnen wird rasch auffallen, dass in diesen Daten manches anders ist:
Alphabetische Liste aller Mitglieder des 18. Deutschen Bundestages, Stand 04.05.2015,
Name,Vorname,Fraktion
Aken, Jan van, Die Linke
Albani, Stephan, CDU/CSU
Albsteiger, Katrin, CDU/CSU
Alpers, Agnes, Die Linke *
Altmaier, Peter, CDU/CSU
Amtsberg, Luise, Bündnis 90/Die Grünen
Andreae, Kerstin, Bündnis 90/Die Grünen
Annen, Niels, SPD
Arndt-Brauer, Ingrid, SPD
Arnold, Rainer, SPD
Auernhammer, Artur, CDU/CSU
Dieser Ausschnitt zeigt die Damen und Herren, deren Namen mit einem „A” beginnen. Und um besser vergleichen zu können, öffnen Sie auch die vorher verwendete, ungeordnete Datei mit dem Text-Editor. Ich zeige Ihnen hier auch einmal die ersten Zeilen auf:
Name;Vorname;Fraktion Zech;Tobias;CDU/CSU Stamm-Fibich;Martina;SPD Friedrich (Hof);Dr. Hans-Peter;CDU/CSU Widmann-Mauz;Annette;CDU/CSU Jung;Andreas;CDU/CSU Meister;Dr. Michael;CDU/CSU Patzelt;Martin;CDU/CSU Baerbock;Annalena;Bündnis 90/Die Grünen
Drei markante Unterschiede sollten Ihnen ins Auge fallen:
- Als Trennzeichen wurde im zuerst verwendeten Beispiel das hier in Deutschland übliche Semikolon verwendet, jetzt (in der geordneten Datei) ist es ein Komma.
- Beim Semikolon-File folgt dem Trenner direkt der folgende Zell-Inhalt, bei der jetzt zu bearbeitenden Datei ist nach dem Komma ein Leerzeichen eingefügt.
- Und auch die erste Zeile der neuen Komma-Datei gehört ganz offensichtlich nicht zu den eigentlichen Daten, es ist eher ein Hinweis, ein erklärender Text.
Schließen Sie gerne wieder die beiden Editor-Fenster und führen Sie den Import der eben gespeicherten *.csv nach dem gleichen Muster wie bereits geschehen durch. Und ich finde es immer wieder imponierend, wie Power Query doch Besonderheiten erkennt:
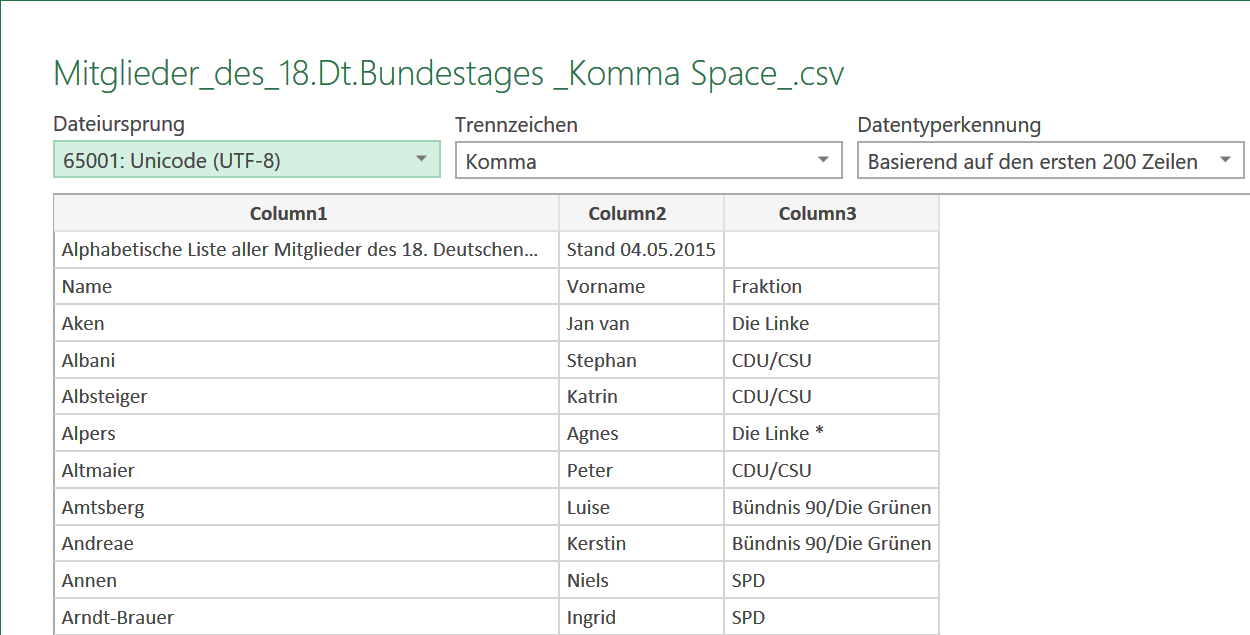
Wichtiges wurde erkannt, offensichtliche Ungereimtheiten wurden beseitigt
Was Sie im Windows-Editor nicht erkennen konnten: Die Codepage dieser Daten ist nicht 1252: Windows sondern 6501: Unicode (UTF‑8). Dieses Format ist weltweit verbreitet und in den USA praktisch Standard. Wie auch die Kommata als Trennzeichen zwischen den „Spalten” der comma separated values-Datei. Beides wurde von PQ erkannt und auch als Default vorgeschlagen. Und bereits hier könen Sie erkennen, dass die Leerschritte nach dem Komma scheinbar gar nicht übernommen worden sind. Sogar die erste Zeile (die nicht zu den Daten gehörende Erklärung) wurd korrekt beim Komma getrennt.
Übernehmen Sie die Daten durch einen Klick auf Daten transformieren und zumindest 1 Überraschung: Die Leerzeichen vor den Vornamen und Fraktionsbezeichnungen sind wieder da. Und klar, das muss auch so sein, denn Power Query kann letztendlich nicht für einen User entscheiden, ob da nun ein führendes Leerzeichen sein soll oder nicht. Insofern war die Vorschau nicht ganz den Tatsachen entsprechend.
Es bleiben noch einige Schritte, um die Abfrage in die gewünschte Form zu bekommen. Zu Beginn sollte die erste Zeile mit dem Hinweis auf den Inhalt der Daten gelöscht werden. Die hat in einer solchen Abfrage nichts zu suchen. Das geht sehr gut über das Menü Start | Zeilen verringern | Zeilen entfernen | Erste Zeilen entfernen und tragen Sie im erschienenen Dialog bei Anzahl von Zeilen den Wert 1 ein. Nach einer Bestätigung mit OK wird diese Zeile sofort verschwunden sein. 😎
Prinzipiell bleiben jetzt noch 2 Schritte zu erledigen. Die führenden Leerzeichen sollen aus den Spalten entfernt und die nunmehr erste Zeile muss noch als Überschrift deklariert werden. In vielen Fällen dürfte es egal sein, welchen Schritt Sie zuerst durchführen. In diesem Fall ist aber eine Ausnahme gegeben; die erste Zeile zeichnet sich dadurch aus, dass hier keine Leerstellen vor der Spaltenüberschrift gegeben sind. Würden Sie also als ersten Schritt das erste Zeichen in jeder Zelle der jeweiligen Spalte entfernen, dann würden die Überschriften unter Umständen um das erste Zeichen gekürzt und damit falsch sein. Darum ist es wichtig, dass Sie zu Beginn die Erste Zeile als Überschrift deklarieren und erst danach die beiden betroffenen Spalten von führenden Leerzeichen befreien.
Den Weg, wie sie die erste Zeile zur Überschrift machen, kennen Sie bereits. Anschließend markieren Sie die Spalte Vorname, Shift oder Strg und ein Klick in die Überschrift Fraktion. Nun ein Rechtsklick in eine der beiden Überschriften und im Kontextmenü Transformieren | Kürzen. Alle führenden und eventuell auch angehängten Leerzeichen werden dadurch entfernt. Sie kennen diese Funktonalität in Plain Excel unter GLÄTTEN(). – Die Abfrage entspricht nun dem Wunschergebnis und Sie können die Query schließen.
Dateiursprung Mac®
Laden Sie von unserem Server bitte diese Datei (Bundestagsmitglieder_unsortiert_mac.csv) herunter. Nachdem Sie den Import-Assistenten gestartet haben werden Sie feststellen, dass hier die Umlaute nicht korrekt wiedergegeben werden. Um mir selbst nach Ihnen die Sache etwas leichter zu machen hatte ich dem File einen „sprechenden” Namen gegeben. 😎 Sie wissen nun also, dass der Dateiursprung von einem Mac® stammt. Das hat aber Power Query jedoch nicht eigenständig erkannt. Wählen Sie im Textfeld Dateiursprung den Eintrag 10000: Westeuropäisch (Mac) und alles ist wieder gut. 🙂
Fast schon „Methusalem”: DOS-Format
Ganz selten begegnen sie mir noch, Daten in „guten alten” DOS-Format. Manches „klassische” Programm der Warenwirtschaft oder ähnlich ist immer noch im Einsatz und tut seinen Dienst. Und nicht umsonst haben Sie in Excel immer noch die Möglichkeit, Daten dieser Code-Basis zu importieren und auch zu exportieren. Und natürlich auch für dieses Format eine Muster-csv (Bundestagsmitglieder_unsortiert_dos.csv).
Andere Codepages
Das Prinzip ist exakt so, wie hierüber diskutiert. Wenn Sie wissen, um welche Codepage es sich handelt, können Sie diese entsprechend wählen. Sie sollten aber wegen der hohen Verbreitung UTF‑8 erst einmal ausprobieren. Falls Sie keinen Anhaltspunkt haben bietet sich vielleicht auch die Möglichkeit an, die Daten erst einmal in Notepad++ zu laden. Dieser Editor kann mitunter die entsprechende Codepage erkennen; es ist aber auch recht komfortabel möglich, per Probieren die korrekte Codierung herauszufinden. Ansonsten kann vielleicht eine Suchmaschine Ihrer Wahl zielführend sein; bei meiner Suche bin ich auf FlowHeater® gestoßen, es gibt aber gewiss noch mehr Möglichkeiten. Zum Ausprobieren habe ich für Sie noch das ANSI-Format (Bundestagsmitglieder_unsortiert_ANSI.csv) und explzit UTF‑8 (Bundestagsmitglieder_unsortiert_utf‑8.csv).
Hat Ihnen der Beitrag gefallen?
Erleichtert dieser Beitrag Ihre Arbeit?
Dann würde ich mich über einen Beitrag Ihrerseits z.B. 2,00 € freuen …